Using Language Models to Identify the Risk of Dementia
The sophisticated application of artificial intelligence (AI) holds fresh potential for healthcare and adjacent fields.
Kai Analytics has thorough experience developing AI web applications in this capacity and can help healthcare providers by leveraging their data to improve public health.
We built a complex AI language pipeline to flag dementia risk indicators in the speech patterns of elderly Japanese individuals for Nabetomo (株式会社Nabe), a Japanese startup that connects senior citizens with a community of conversation partners through secure video sessions. This included applying methods such as natural language processing and speech emotion recognition to create a proof-of-concept for a set of metrics for the participants.

What We Did
We developed a robust AI application to detect dementia risk using large language models. We:
Built a complex AI language pipeline.
Calculated dementia indicators using speech complexity and answer cohesion.
Built speech profiles for each elderly individual and trended their speech outcomes month-over-month.
Visualized themes from participants to help them share important moments from their lives with their family.
Solution & Deliverables
We knew that creating a solution that would meet Nabetomo’s needs would require a carefully established process. We carefully mapped how our use of technology would achieve Nabetomo’s goals and find the most important insights from their data.
Analytics Techniques
- We investigated speech emotion analysis and voice analysis that measures factors such as:
- speaking time and length of pauses to detect utterance and syllable boundaries
- frequency contours and peaks
- Other techniques extracted audio features, classified unknown sounds and excluded silence from longer recordings.
- We performed supervised and unsupervised segmentation
- We trained regression models and applied dimensionality reduction to visualize audio data and content similarities.
Complex AI Application
Analyzing speech recordings poses numerous challenges – unclear speech, conversation partners accidentally speaking over each other, and security concerns around security. We built an intricate AI pipeline to:
- Machine-transcribe conversational speech from almost a year’s worth of recorded video calls in Japanese.
- Clean the data and separated it into meaningful sections for analysis.
- Use both the audio and transcriptions to investigate speech patterns, sentiment, and the topics discussed.
- Process and consolidate the data into benchmark measures and visualize it in a secure web dashboard.
We worked closely with Nabetomo to ensure each step aligned with their goals for the data.
AI Speech Analysis
The analysis is rigorous and captures the following features:
- Complexity of words used
- Question and answer cohesion
- Percentage of conversation sharing
- Speaker confidence and sentiment
- Topics discussed
These features are important for identifying potential signs of dementia, such as the reduction in complex words, answers that do not line up with the questions asked, and a lower participation in the conversation.
As an added value, this process captures discussions related to key memories, allowing participants to share them with their family. For example, a happy memory of a childhood birthday, experiences during a recent vacation, and tragic moments from living through the war.
Benchmarking and Security
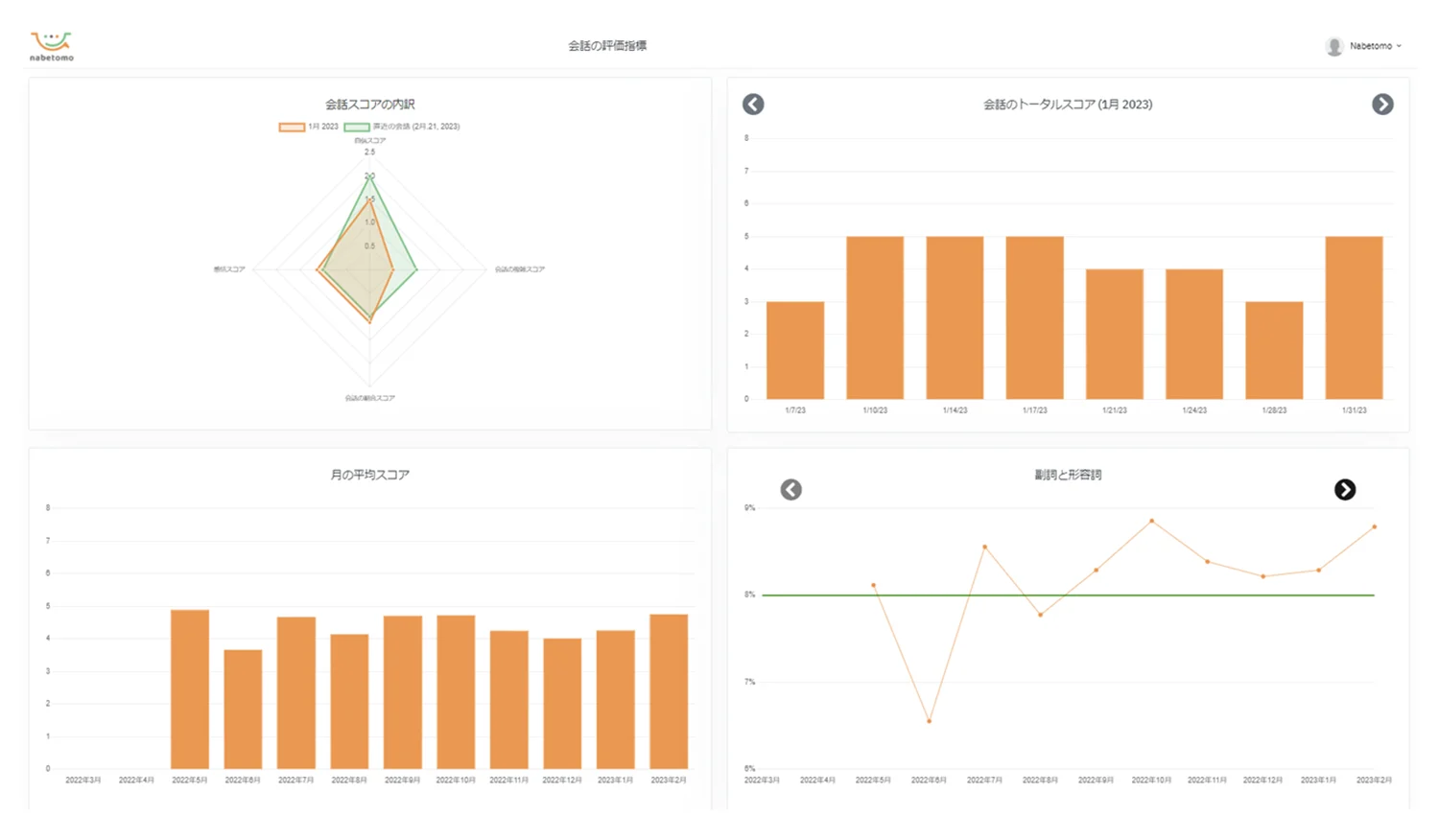
These features were analyzed to produce a conversational score that can point towards the risk of dementia. This score was trended over time so participants and their family could quickly respond to changes in their health. Our models also flag security risks such as inadvertent discussions about personal banking. This helps keep participant’s data secure and protect their privacy.
Participating in this process contributes to encouraging early diagnosis of dementia. At the same time, it is promoting social interaction, which can help prevent or delay the onset of dementia.

Qualitative Data Visualization – Preserving Memories
For many participants, the project yielded not only important data on their speech, but also records of memories discussed with their conversation partner. For example, a happy memory of a childhood birthday, experiences during a recent vacation, and tragic moments from living through the war. This data serves as an important keepsake and record of their lives.

Dashboard – Benchmarking and Monitoring
Our application included a dashboard for monitoring the data. The graphs show the “conversation score,” which indicates the presence of potential risk signs, tracked across session and over time.
Results & Impact
In addition to creating a supportive and meaningful experience for all platform users, our work on this project resulted in a prototype that could be used as the basis for further research.
Funding Awarded
User Satisfaction
Result Metrics
- We developed a topic estimation model as part of our proprietary AI model, Unigrams, and provided a custom, standalone version of the model.
- The model classifies each chunk of language, clusters them into topics and then produces bigram graphs to visualize the most common terms and relationships.